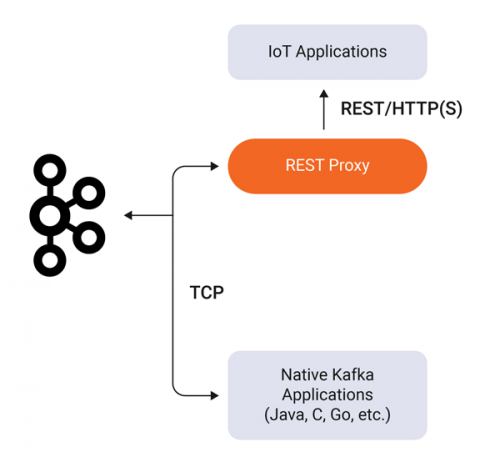
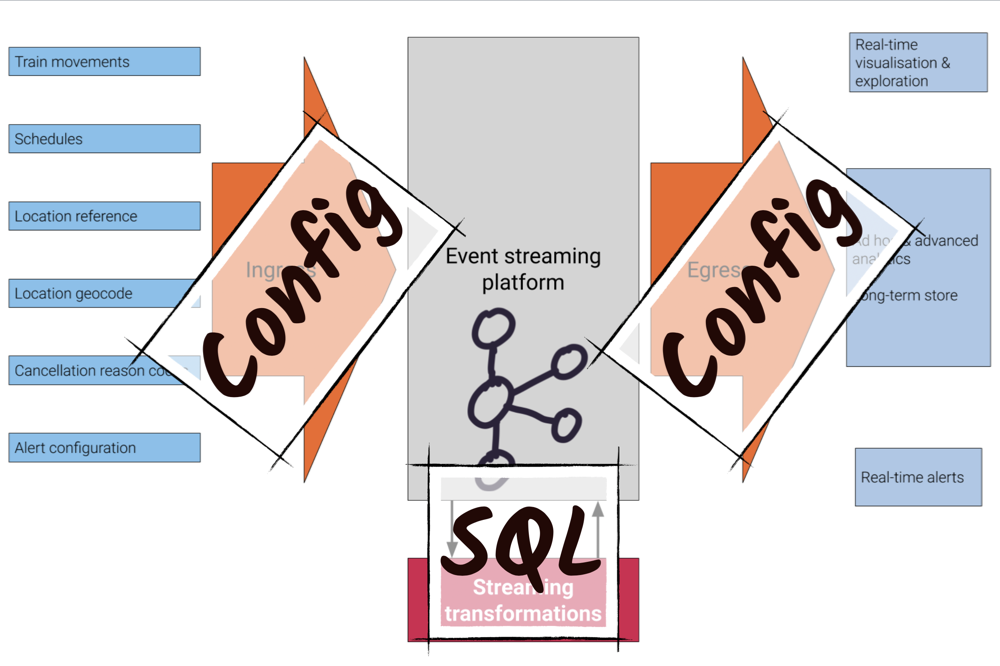
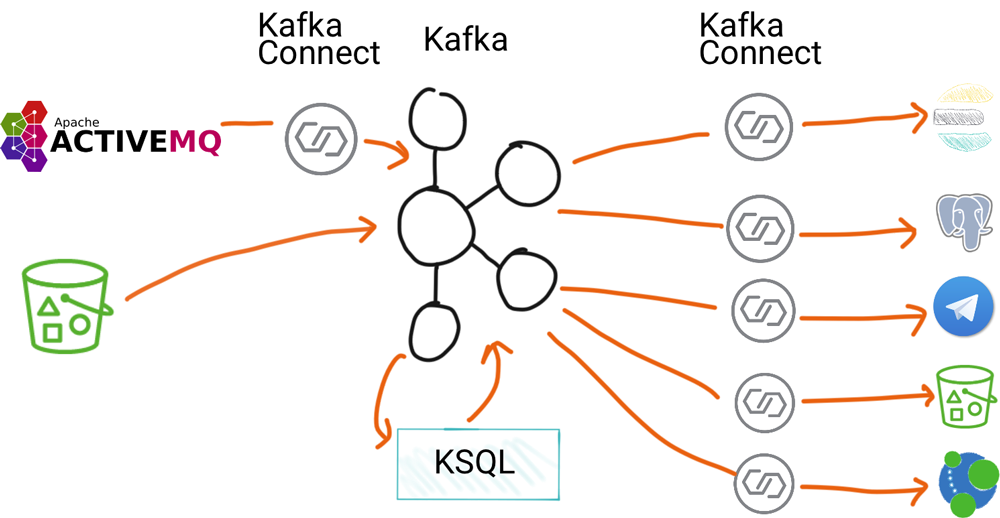
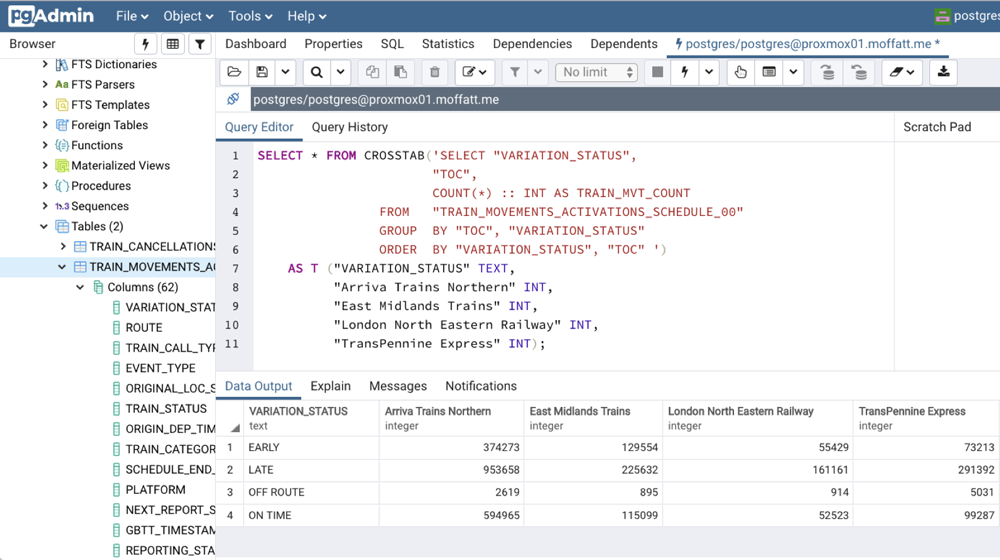
In 2011, Marc Andressen wrote an article called Why Software is Eating the World. The central idea is that any process that can be moved into software, will be. This has become a kind of shorthand for the investment thesis behind Silicon Valley’s current wave of unicorn startups. It’s also a unifying idea behind the larger set of technology trends we see today, such as machine learning, IoT, ubiquitous mobile connectivity, SaaS, and cloud computing. These trends are all, in different ways, making software more plentiful and capable and are expanding its reach within companies.
I believe that there is an accompanying change—one that is easy to miss, but equally essential. It isn’t just that businesses use more software, but that, increasingly, a business is defined in software. That is, the core processes a business executes—from how it produces a product, to how it interacts with customers, to how it delivers services—are increasingly specified, monitored, and executed in software. This is already true of most Silicon Valley tech companies, but it is a transition that is spreading to all kinds of companies, regardless of the product or service they provide.
To make clear what I mean, let’s look at an example: the loan approval process from a consumer bank. This is a business process that predates computers entirely. Traditionally this was a multi-week process where individuals such as a bank agent, mortgage officer, and credit officer each collaborated in a manual process. Today this process would tend to be executed in semi-automated fashion, each of these functions has some independent software applications that help the humans carry out their actions more efficiently. However this is changing now in many banks to a fully automated process where credit software, risk software, and CRM software communicate with each other and provide a decision in seconds. Here, the bank loan business division has essentially become software. Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process.
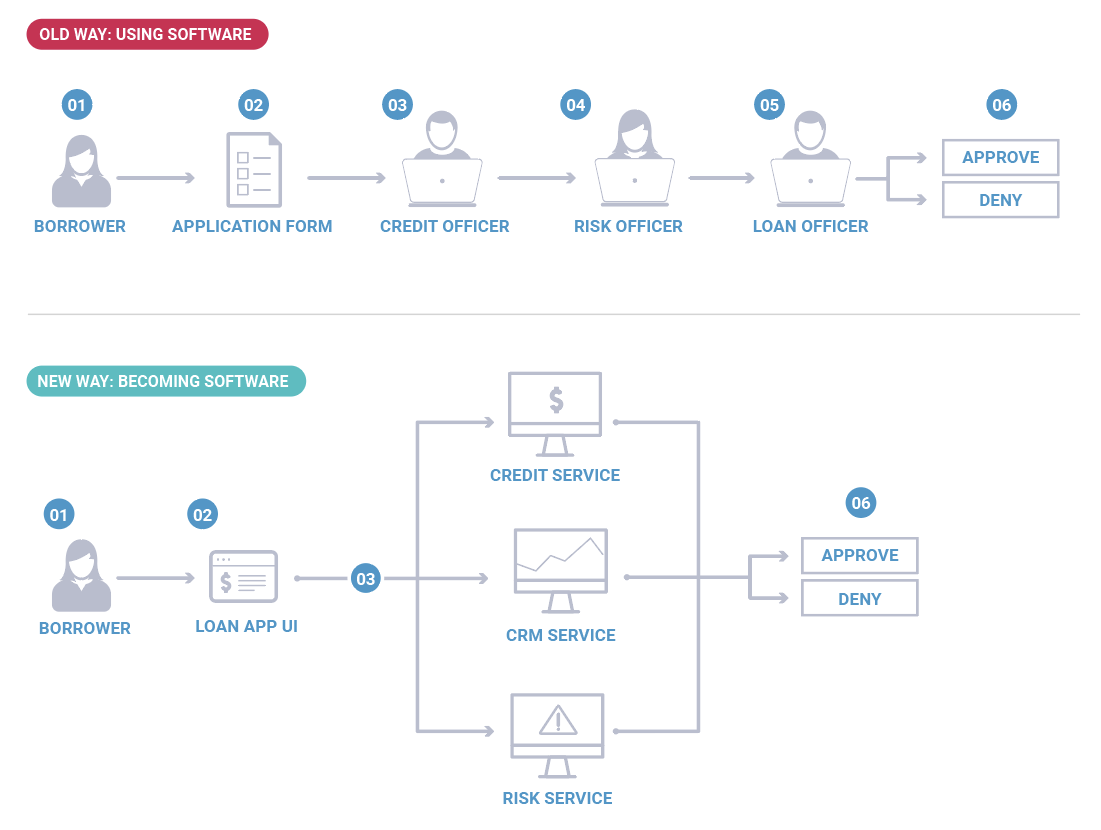
Companies aren’t just using software as a productivity aid for human processes, they are building out whole parts of the business in code.
This transition has many significant implications, but my focus will be on what it means for the role and design of the software itself. The purpose of an application, in this emerging world, is much less likely to be serving a UI to aid a human in carrying out the activity of the business, and far more likely to be triggering actions or reacting to other pieces of software to carry out the business directly. And, while this is fairly simple to comprehend, it raises a big question:
Are traditional database architectures a good fit for this emerging world?
Databases, after all, have been the most successful infrastructure layer in application development. However virtually all databases, from the most established relational DBs to the newest key-value stores, follow a paradigm in which data is passively stored and the database waits for commands to retrieve or modify it. What’s forgotten is that the rise of this paradigm was driven by a particular type of human-facing application in which a user looks at a UI and initiates actions that are translated into database queries. In our example above, it’s clear a relational database is built to support applications that would aid the human parts in that 1–2 week loan approval process; but is it the right fit for bringing together the full set of software that would comprise a real-time loan approval process built on continuous queries on top of ever-changing data?
Indeed, it’s worth noting that of the applications that came to prominence with the rise of the RDBMS (CRM, HRIS, ERP, etc.), virtually all began life in the era of software as a human productivity aid. The CRM application made the sales team more effective, the HRIS made the HR team more effective, etc. These applications are all what software engineers call “CRUD” apps. They help users create, update, and delete records, and manage business logic on top of that process. Inherent in this is the assumption that there is a human on the other end driving and executing the business process. The goal of these applications is to show something to a human, who will look at the result, enter more data into the application, and then carry out some action in the larger company outside the scope of the software.
This model matched how companies adopted software: in bits and pieces to augment organizations and processes that were carried out by people. But the data infrastructure itself had no notion of how to interconnect or react to things happening elsewhere in the company. This led to all types of ad hoc solutions built up around databases, including integration layers, ETL products, messaging systems, and lots and lots of special-purpose glue code that is the hallmark of large-scale software integration.
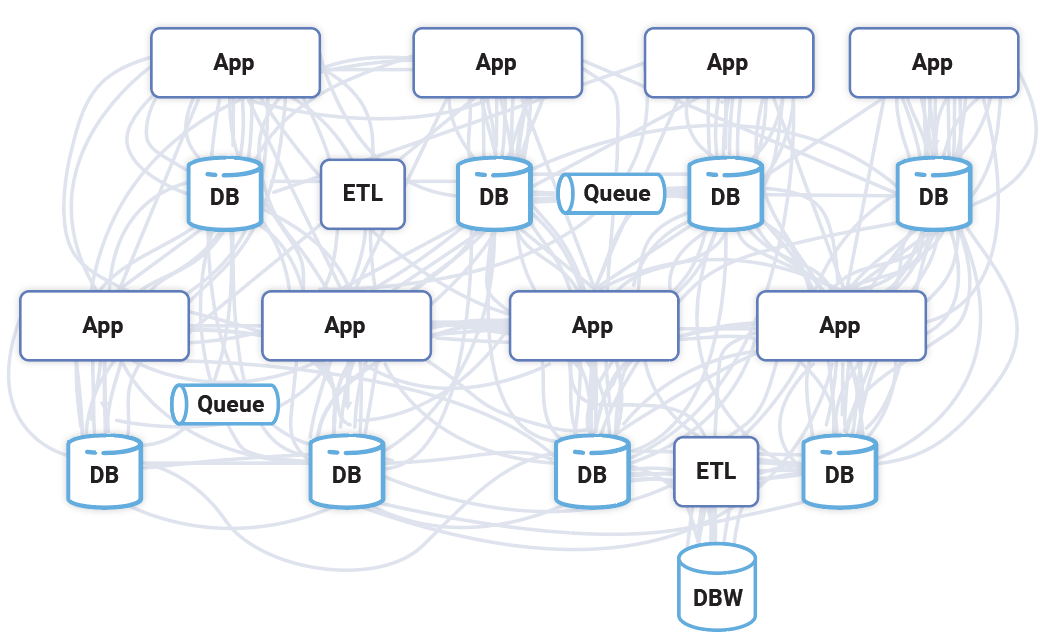
Because databases don’t model the flow of data, the interconnection between systems in a company is a giant mess.
Emergence of event streams
So what new capabilities do our data platforms need when the primary role of software is not to serve a UI but to directly trigger actions or react to other pieces of software?
I believe the answer starts with the concept of events and event streams. What is an event? Anything that happens—a user login attempt, a purchase, a change in price, etc. What is an event stream? A continually updating series of events, representing what happened in the past and what is happening now.
Event streams present a very different paradigm for thinking about data from traditional databases. A system built on events no longer passively stores a dataset and waits to receive commands from a UI-driven application. Instead, it is designed to support the flow of data throughout a business and the real-time reaction and processing that happens in response to each event that occurs in the business. This may seem far from the domain of a database, but I’ll argue that the common conception of databases is too narrow for what lies ahead.
Apache Kafka® and its uses
I’ll sketch out some of the use cases for events by sharing my own background with these ideas. The founders of Confluent originally created the open source project Apache Kafka while working at LinkedIn, and over recent years Kafka has become a foundational technology in the movement to event streaming. Our motivation was simple: though all of LinkedIn’s data was generated continuously, 24 hours a day, by processes that never stopped, the infrastructure for harnessing that data was limited to big, slow, batch data dumps at the end of the day and simplistic lookups. The concept of “end-of-the-day batch processing” seemed to be some legacy of a bygone era of punch cards and mainframes. Indeed, for a global business, the day doesn’t end.
It was clear as we dove into this challenge that there was no off-the-shelf solution to this problem. Furthermore, having built the NoSQL databases that powered the live website, we knew that the emerging renaissance of distributed systems research and techniques gave us a set of tools to solve this problem in a way that wasn’t possible before. We were aware of the academic literature on “stream processing,” an area of research that extended the storage and data processing techniques of databases beyond static tables to apply them to the kind of continuous, never-ending streams of data that were the core of a digital business like LinkedIn.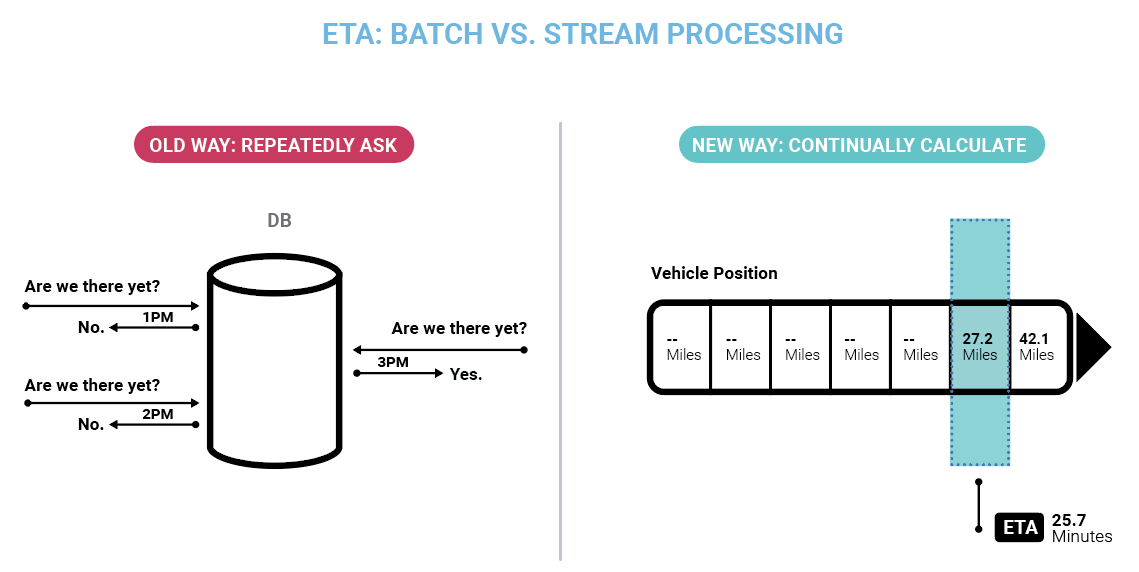
We’re all familiar with the age-old question: “Are we there yet?” The traditional database is a bit like a child and has no way to answer this other than just asking over and over again. With stream processing, the ETA becomes a continuous calculation always in sync with the position of the car.
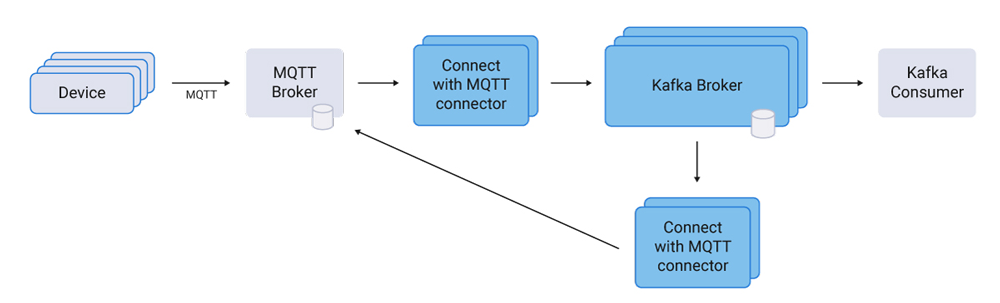
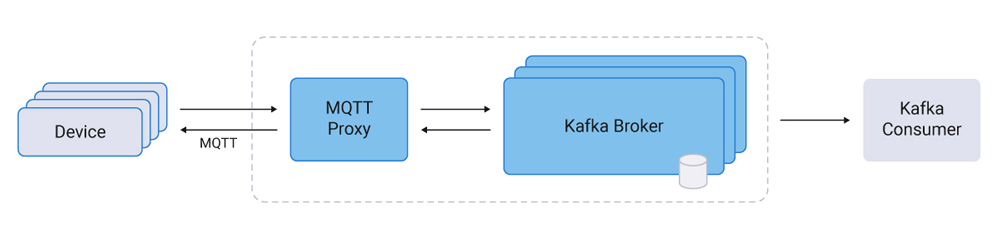
In a social network, an event could represent a click, an email, a login, a new connection, or a profile update. Treating this data as an ever-occurring stream made it accessible to all the other systems LinkedIn had.
![]()
Our early use cases involved populating data for LinkedIn’s social graph, search, and Hadoop and data warehouse environments, as well as user-facing applications like recommendation systems, newsfeeds, ad systems, and other product features. Over time, the use of Kafka spread to security systems, low-level application monitoring, email, newsfeeds, and hundreds of other applications. This all happened in a context that required massive scale, with trillions of messages flowing through Kafka each day, and thousands of engineers building around it.
After we released Kafka as open source, it started to spread well outside LinkedIn, with similar architectures showing up at Netflix, Uber, Pinterest, Twitter, Airbnb, and others.
As we left LinkedIn to establish Confluent in 2014, Kafka and event streams had begun to garner interest well beyond the Silicon Valley tech companies, and moved from simple data pipelines to directly powering real-time applications.
Some of the largest banks in the world now use Kafka and Confluent for fraud detection, payment systems, risk systems, and microservices architectures. Kafka is at the heart of Euronext’s next-generation stock exchange platform, processing billions of trades in the European markets.
In retail, companies like Walmart, Target, and Nordstrom have adopted Kafka. Projects include real-time inventory management, in addition to integration of ecommerce and brick-and-mortar facilities. Retail had traditionally been built around slow, daily batch processing, but competition from ecommerce has created a push to become integrated and real time.
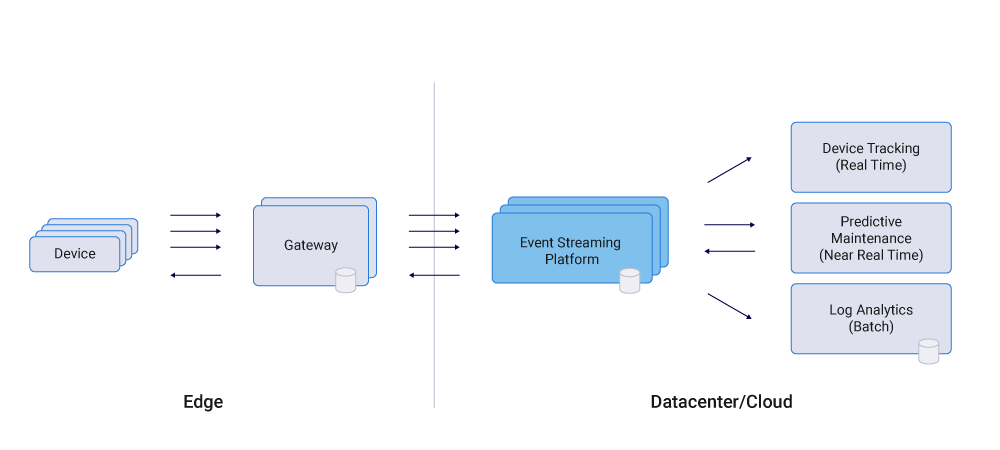
A number of car companies, including Tesla and Audi, have built out the IoT platform for their next-generation connected cars, modeling car data as real-time streams of events. And they’re not the only ones doing this. Trains, boats, warehouses, and heavy machinery are starting to be captured in event streams as well.
What started as a Silicon Valley phenomenon is now quite mainstream with hundreds of thousands of organizations using Kafka, including over 60% of the Fortune 100.
Event streams as the central nervous system
In most of these companies, Kafka was initially adopted to enable a single, scalable, real-time application or data pipeline for one particular use case. This initial usage tends to spread rapidly within a company to other applications.
The reason for this rapid spread is that event streams are all multi-reader: an event stream can have any number of “subscribers” that process, react, or respond to it.
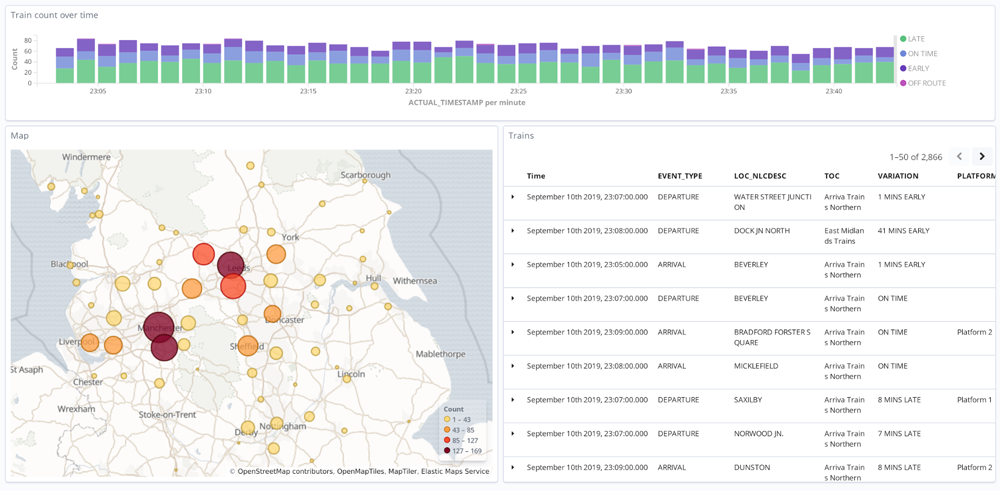
To take retail as an example, a retailer might begin by capturing the stream of sales that occur in stores for a single use case, say, speeding up inventory management. Each event might represent the data associated with one sale: which products sold, what store they sold in, etc. But though usage might start with a single application, this same stream of sales is critical for systems that do pricing, reporting, discounting, and dozens of other use cases. Indeed, in a global retail business there are hundreds or even thousands of software systems that manage the core processes of the business from inventory management, warehouse operations, shipments, price changes, analytics, and purchasing. How many of these core processes are impacted by the simple event of a sale of a product taking place? The answer is many or most of them, as selling a product is one of the most fundamental activities in retail.
This is a virtuous cycle of adoption. The first application brings with it critical data streams. New applications join the platform to get access to those data streams, and bring with them their own streams. Streams bring applications, which in turn bring more streams.
The core idea is that an event stream can be treated as a record of what has happened, and any system or application can tap into this in real time to react, respond, or process the data stream.
This has very significant implications. Internally, companies are often a spaghetti-mess of interconnected systems, with each application jury-rigged to every other. This is an incredibly costly, slow approach. Event streams offer an alternative: there can be a central platform supporting real-time processing, querying, and computation. Each application publishes the streams related to its part of the business and relies on other streams, in a fully decoupled manner.
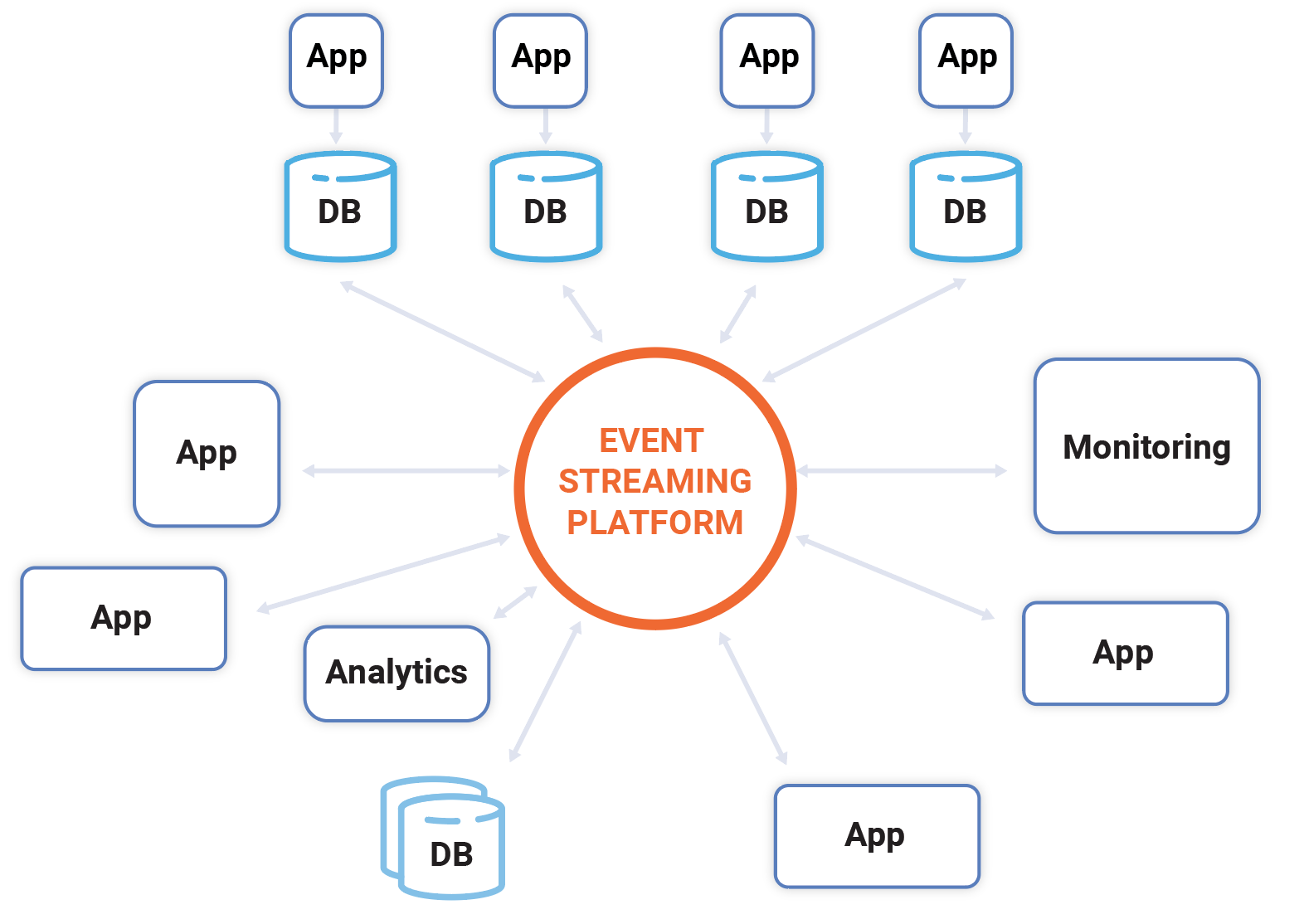
In driving interconnection, the event streaming platform acts as the central nervous system for the emerging software-defined company. We can think of the individual, disconnected UI-centric applications as a kind of single-celled organism of the software world. One doesn’t get to an integrated digital company by simply stacking many of these on top of one another, any more than a dog could be created from a pile of undifferentiated amoebas. A multicell animal has a nervous system that coordinates all the individual cells into a single entity that can respond, plan, and act instantaneously to whatever it experiences in any of its constituent parts. A digital company needs a software equivalent to this nervous system that connects all its systems, applications, and processes.
This is what makes us believe this emerging event streaming platform will be the single most strategic data platform in a modern company.
The event streaming platform: Databases and streams must join together
Doing this right isn’t just a matter of productizing the duct tape companies have built for ad hoc integrations. That is insufficient for the current state, let alone the emerging trends. What is needed is a real-time data platform that incorporates the full storage and query processing capabilities of a database into a modern, horizontally scalable, data platform.
And the needs for this platform are more than just simply reading and writing to these streams of events. An event stream is not just a transient, lossy spray of data about the things happening now—it is the full, reliable, persistent record of what has happened in the business going from past to present. To fully harness event streams, a real-time data platform for storing, querying, processing, and transforming these streams is required, not just a “dumb pipe” of transient event data.
Combining the storage and processing capabilities of a database with real-time data might seem a bit odd. If we think of a database as a kind of container that holds a pile of passive data, then event streams might seem quite far from the domain of databases. But the idea of stream processing turns this on its head. What if we treat the stream of everything that is happening in a company as “data” and allow continuous “queries” that process, respond, and react to it? This leads to a fundamentally different framing of what a database can be.
In a traditional database, the data sits passively and waits for an application or person to issue queries that are responded to. In stream processing, this is inverted: the data is a continuous, active stream of events, fed to passive queries that simply react and process that stream.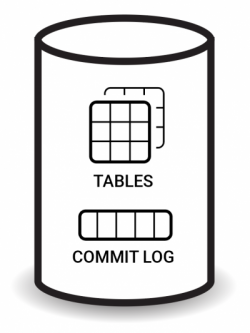
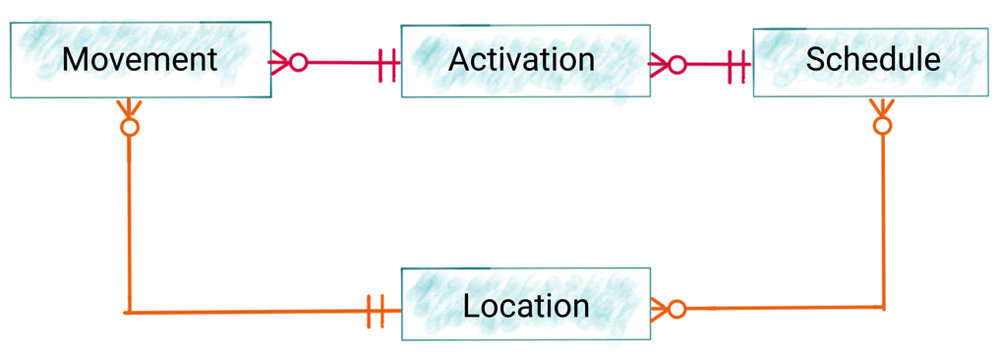
In some ways databases already exhibited this duality of tables and streams of events in their internal design if not their external features. Most databases are built around a commit log that acts as a persistent stream of the data modification events. This log is usually nothing more than an implementation detail in traditional databases, not accessible to queries. However in the event streaming world the log needs to become a first-class citizen along with the tables it populates.
The case for integrating these two things is based on more than database internals, though. Applications are fundamentally about reacting to events that occur in the world using data stored in tables. In our retail example, a sale event impacts the inventory on hand (state in a database table), which impacts the need to reorder (another event!). Whole business processes can form from these daisy chains of application and database interactions, creating new events while also changing the state of the world at the same time (reducing stock counts, updating balances, etc.).
Traditional databases only supported half of this problem and left the other half embedded in application code. Modern stream processing systems like KSQL are bringing these abstractions together to start to complete what a database needs to do across both events and traditional tables of stored data, but the unification of events with database is a movement that is just beginning.
Confluent’s mission
Confluent’s mission is to build this event streaming platform and help companies begin to re-architect themselves around it. The founders and a number of its early employees have been working on this project since even before the company was born.
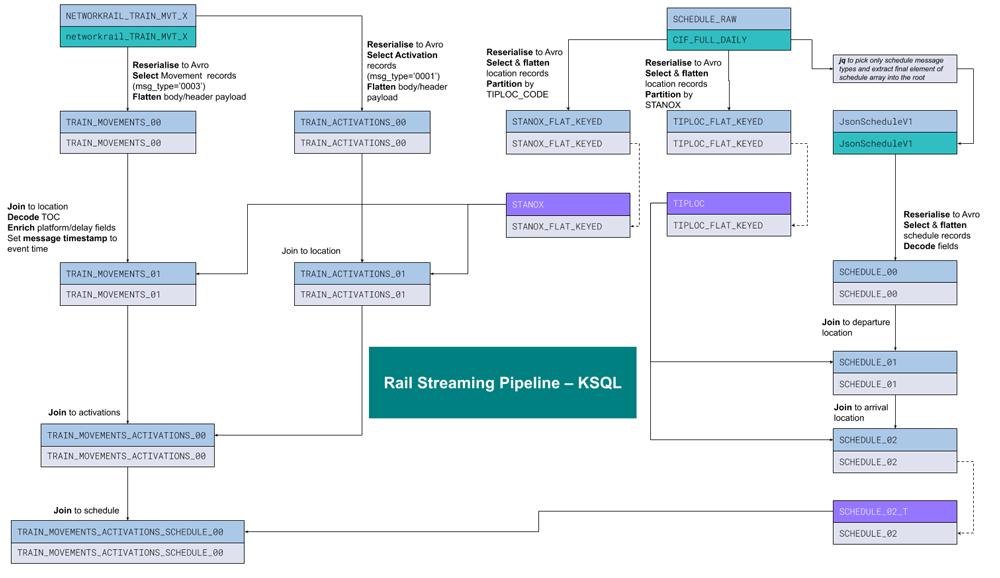
Our approach to building this platform is from the bottom up. We started by helping to make the core of Kafka reliably store, read, and write event streams at massive scale. Then we moved up the stack to connectors and KSQL to make using event streams easy and approachable, which we think is critical to building a new mainstream development paradigm.
![]()
We’ve made this stack available as both a software product as well as a fully managed cloud service across the major public cloud providers. This allows the event streaming platform to span the full set of environments a company operates in and integrate data and events across them all.
There are huge opportunities for an entire ecosystem to build up on top of this new infrastructure: from real-time monitoring and analytics, to IoT, to microservices, to machine learning pipelines and architectures, to data movement and integration.
As this new platform and ecosystem emerges, we think it can be a major part of the transition companies are going through as they define and execute their business in software. As it grows into this role I think the event streaming platform will come to equal the relational database in both its scope and its strategic importance. Our goal at Confluent is to help make this happen.
Jay Kreps is the CEO of Confluent as well as one of the co-creators of Apache Kafka. He was previously a senior architect at LinkedIn.
I’ll be sharing more about the impact of Apache Kafka and major developments to come during my keynote at Kafka Summit San Francisco, which takes place from September 30th to October 1st. If you’re interested in attending, feel free to register with the code blog19 to get 30% off.












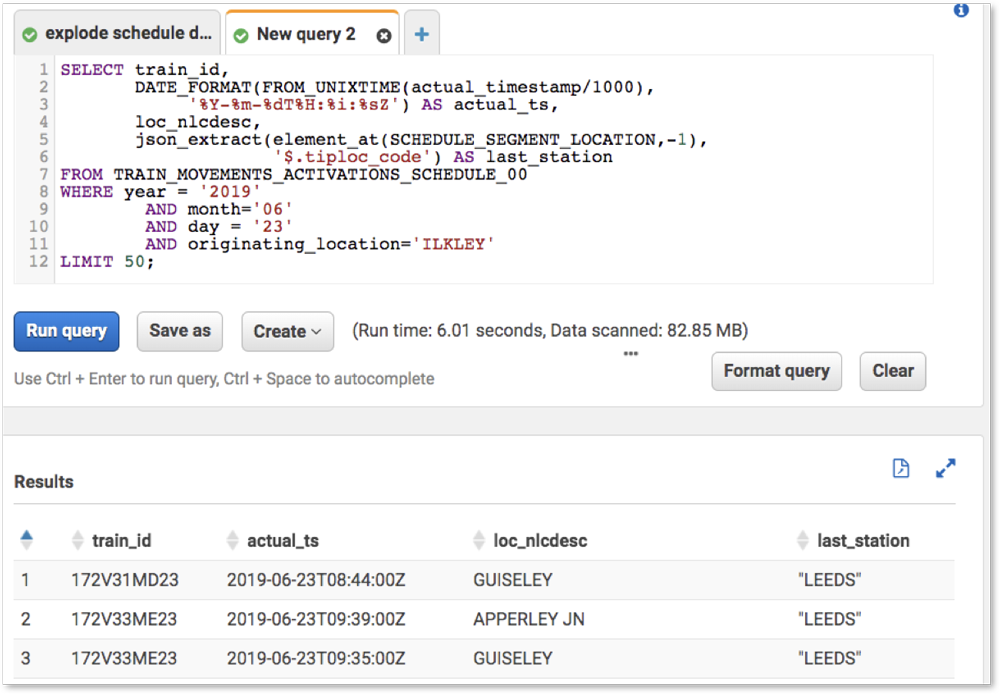
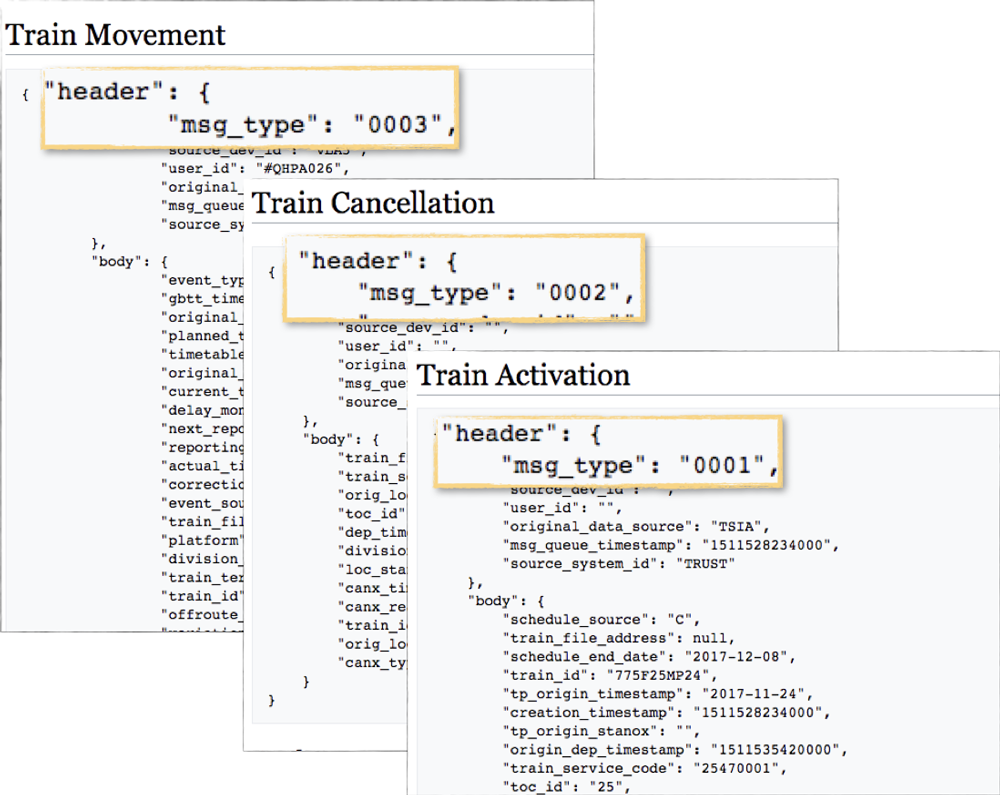
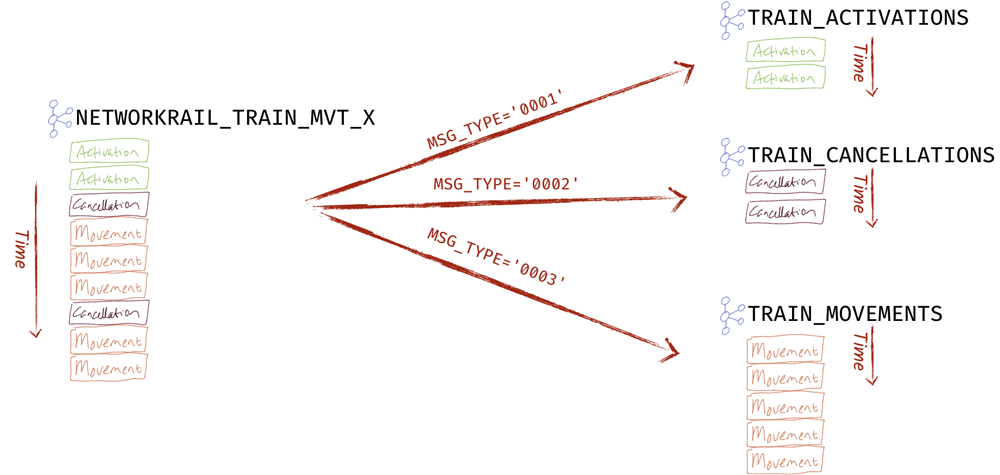
 The
The